Table of contents-
Intro
Minkowski space, metric, and paraboloid
Understanding symmetry and transformations
Projections of hyperbolic space (Poincare, Klein, and Gans)
Things to see and do in hyperbolic space
Implementation Iteration 1- Matrices
Implementation iteration 2- Polar Transform
Implementation iteration 3- Tree Traversal
Implementation iteration 4- Infinite generation
Implementation iteration 5- Structure generation
Extras- Generating 3d models!
Recently, I have found an interest in rendering and “simulating” hyperbolic space, inspired mainly by CodeParade’s new game in development, Hyperbolica- an adventure game set in hyperbolic/spherical spaces (Wishlist it on steam). I already had a passing interest in strange geometries, after watching his previous video on non-Euclidian worlds, and being fond of MC Escher’s art, so I was dead-set on figuring it out for myself. He did say that the hyperbolic engine was several years in the works, but when has time ever been an issue.
Without any idea on how to implement such a system, I did some research into other hyperbolic games, where I found HyperRogue- a rogue-like game in hyperbolic space where you dispatch foes, collect loot, and explore various lands with unique mechanics that make use of hyperbolic space. I promptly wasted several afternoons playing it. I’d like to think that this built up my intuition of hyperbolic space. But most importantly, HyperRogue’s creator had a page on how his game was implemented, but there is one big issue. I have no idea how hyperbolic space works, how it is represented, or how you would traverse it.
Here’s where I hit the books. What is hyperbolic space? According to wikipedia, hyperbolic space in N dimensions is a maximally symmetric, simply connected, N-dimensional Riemannian Manifold with constant negative sectional curvature. What on earth does that mean? Well, maximally symmetric means that all points and all orientations are essentially the same, and simply connected means that there are no holes or defects in the space, and N-dimensional Riemannian Manifold says that there is some way of measuring vector lengths, and zooming in yields an approximately flat space. The constant negative sectional curvature is the tricky part, and the only factor that makes hyperbolic space different from euclidian and spherical space. There are tons of formulas and relations in differential geometry that gives you ways of measuring curvature and etc, but at this point I was stumped. Maybe I know all the math and definitions, but how am I supposed to put numbers on things? How am I supposed to represent coordinates and to transformations?

When I was first trying to find an effective model of hyperbolic space, i.e. a way of giving a coordinate system and parametrisation to points on the space, I ran into trouble. The first thing that came to my head as a model of hyperbolic space was a hyperbolic paraboloid- the classic saddle shaped Pringles chip surface. Even though the hyperbolic paraboloid has negative curvature everywhere, the magnitude of curvature decreases as the distance from the origin increases, so it isn’t perfectly hyperbolic. Perhaps hyperbolic space is better represented by a hyperboloid of one sheet? Clearly not. Firstly, it is topologically congruent to a cylinder, not a plane. Secondly, as we go farther from the origin in the z axis, the hyperboloid becomes tangent to a cone, which has zero gaussian curvature- so it doesn’t have constant negative curvature. So are we forced to represent hyperbolic space by a horrible crumpled up mess? Yes and no.

Minkowski space, metric, and paraboloid
Most of the visualisations of hyperbolic spaces we’ve seen so far display the whole space compressed into a disc- called a Poincare disc. But points aren’t represented on the 2d disc. It turns out that hyperbolic space in math is represented by the one surface of a hyperboloid of 2 sheets, called the Minkowski hyperboloid. The Poincare disc view is just a projection of the hyperboloid onto the plane (analogous to stereographic projection of a sphere onto the plane). The Minkowski hyperboloid is used in representations of spacetime, and is used internally in HyperRogue (and probably Hyperbolica also). If we say x is the vertical axis (you’ll see why later), the point 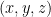


So how is Minkowski space different from regular Euclidean space? Distance in Minkowski space is measured differently than Euclidean space- it has a different Metric, which is an idea from differential geometry. A metric essentially gives you a formula for lengths in a space. The metric in euclidian space is 



I’m sure we all have a good understanding of the euclidean metric, but what does it mean for a space to have a different metric? Well, imagine a standard map of the earth, and I asked you the distance between LA and Hong Kong. A map of course is 2d, and “flat” so we could easily parametrize points on it with two coordinates 

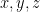


But there is a simpler approach: just figure out the metric in terms of 
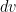
All that just to say that the Minkowski metric is different; the Minkowski metric is 


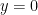


The green vector/line element shown above has this exact “issue”- it has no defined length because its 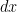

Why? Let’s see how this explains a well known property of hyperbolic space; Circles circumference increases exponentially with radius, not linearly like in euclidean space. Well, consider a circle centered at the origin of the hyperboloid ( the point (1,0,0)). Starting from the origin, we need to travel a distance r in a direction, let’s say the Z direction. Using some nifty calculus, we can figure out what point we will end up at, by integrating enough line element lengths until we reached a total length r. Around the origin, the magnitude of dx compared to dz is low, so moving a distance of 1 unit will take us to a point with z coordinate only slightly more than 1. But as our z value increases, dx becomes larger and the deficiency in length becomes more apparent. Even if we increase our z value by one, the change in total distance travelled will be quite small- hopefully now it makes sense that our z value will have to grow much faster than the r value to keep up. The exact math tells us that the z value after traveling a total distance of r is the hyperbolic sin of r, sinh(r).

Quick note on hyperbolic trig functions: the fact that the z value of the final point is exactly hyperbolic sine of r is no coincidence, it is essentially the definition of hyperbolic sine (sinh). Thinking back to the definition of the circular trig functions, we say that sine r is the y coordinate value of a point after travelling a distance r across the arc of the circle. We are doing the exact same thing for the hyperbolic trig functions. Also this is why x is commonly chosen as the up direction of the Minkowski hyperboloid, so aligns with the cos-> x, sin -> y notion. The hyperbolic trig functions are also described as the even and odd components of 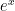



Back to are argument about circle circumferences- we know that a circle of radius r in hyperbolic space will have a point with Z value sinh(r), but what does this say about the circumference of the circle? By a symmetry argument, it would make sense that the all the X values of points on the circle are the same, so we could imagine taking a cross section with x= cosh(r), and this would let us see the circle. But since all points on the circle have the same x coordinate, each line element tangent to the circle would have 


Understanding symmetry and transformations in hyperbolic space
So now we have some intuition for why the Minkowski hyperboloid has negative curvature everywhere, but at this point I was still wondering why the hyperboloid was maximally symmetric, i.e. every point is exactly identical in terms of its curvature and neighbourhood. The best way to realise this is to note that any point on the hyperboloid can be transformed to be located at the origin, while keeping the geometry intact. The Minkowski hyperboloid is convenient in that the transformation that does this is a linear transformation in x,y and z. First, before we get into hyperbolic space transformations, its useful to review transformations in 2d euclidian space. We know every point and orientation in euclidean space is symmetric to any other, because we can bring any point to another with a transform that does not change the structure of space- called an affine transformation. In 2d space, an affine transformation is a linear transform that rotates, reflects, and translates space. It’s easy to represent points with just (x,y) coordinates, but in order to make the math more concise, points are often represented in 3d space, on a plane with z=1, so that all rotations and translations can be represented with a single 3 by 3 transformation matrix, which is used commonly in code. Think about the z=1 plane in Euclidean 2 space as being analogous to the

The 3 by 3 transformation matrix can’t be any matrix though, it is constrained in two ways. 1- The transformation can’t take any point off of the plane, the z coordinate after applying the transformation must remain 1. 2- The transformation can’t stretch or warp space in any way, this essentially boils down to the matrix being part of the SU3 group of matrixes. Solving for both of these constraints tells you that the matrix is a combination of rotation in x and y, plus a translation.
 is the angle of rotation, and
is the angle of rotation, and  are translations in the x and y directions
are translations in the x and y directionsIt is also convenient to break down the affine transformation into a rotation matrix and a translation matrix, which can be applied individually and can be combined to create other coordinate systems like polar coordinates :
The same process can be applied to the Minkowski space and hyperboloid yeilding the following matrixes. For vectors of the form (x,y,z) where
Rotation of angle

In hyperbolic space, translations behave differently. For example, if you take 1 unit in the y direction, then 1 unit in the z direction, the point you reach is NOT the same point starting by moving 1 in z and then 1 in y. As a result of this, it doesn’t make sense to define points/translations in hyperbolic space as a y coordinate and a z coordinate (polar coordinates tend to make more sense), and therefore there are separate translation matrices for translation in y and translation in z.
In order to verify this, lets translate the origin (1,0,0) a distance of r- this should agree with our previous conclusion about a point a distance r from the origin in the z direction, which it does.
There is a separate, but similar matrix for translating in the y direction:
By combining these 3 matrices, we can get a general parameterisation of a affine transformation in hyperbolic space. I found that the most convenient set of rotation and translation matrixes resulted in what I call a polar transformation. A polar transformation begins with a rotation of angle 


With all affine transformations represented by polar transforms, we only need to keep track of three real numbers (n, r, and m), not 9- and there are formulas (albeit not very simple ones) for the resulting polar transform after multiplying two polar transforms. This, and other benefits of using the polar transform will be discussed on the implementation section of this blog post.
Projections of hyperbolic space (Poincare, Klein, and Gans)

At this point, the internal representation of hyperbolic space on the Minkowski hyperboloid makes sense, but the details of how to display the space are still up in the air. Of course, we could just render the points in 3d space, but each 2d projection has useful properties.
The first projection shown is the Poincare projection, which is the most common view of hyperbolic space, used in HyperRogue, and in MC Escher’s art. All of the hyperbolic paraboloid is projected onto a unit circle. The projection also is conformal, meaning angles between lines are preserved, although lengths and areas are clearly not. The Poincare projection is the only conformal projection of hyperbolic space on the plane. All straight lines on the Poincare disc are seen as circles that are perpendicular to the circle of the disc, which makes this visualisation the most feasible to draw with ruler and compass. This projection is achieved by projecting every point on the hyperboloid down to the plane (x=0) on lines passing through the point (-1,0,0). A visual using my implementation is shown below- see how the green point is projected along a line passing through (-1,0,0).

The second projection is also generated by projecting the hyperbola onto the plane with lines passing through a specific point. The Beltrami–Klein projection is notable in that all straight lines in hyperbolic space project onto straight lines on the Klein disc. Other than this property, the Beltrami–Klein projection is devoid of may other conveniences; it does not preserve angles, lengths or volumes- in fact it the compression to the edge of the disc is even harsher that the poincare Projection. This projection is achieved by projecting onto the plane (x=1) with lines through the origin (0,0,0). (Eugenio Beltrami, was an Italian mathematician/geometer that discovered many facts about hyperbolic space, and was the first person to find these 3 projections)

Lastly the Gans projection is simply projecting orthogonally down onto a plane. Unlike the Poincare and Klein projections, the Gans projection uses all of the plane to represent hyperbolic space. The Gans projection doesn’t have too many special properties, other than lines being represented by hyperbolas.
Several other hyperbolic projections exist, including the Poincare half plane, the inverted Poincare, the hemisphere model, and several others that preserve area, aspect ratio, ect. In fact, almost every projection of a sphere onto the plane has an analogous projection for the hyperboloid, with similar properties.
Things to see and do in hyperbolic space
There are a lot of structures and geometries that exist in hyperbolic space, that don’t exist in euclidean space. One of the most interesting structures are impossible tessellations- tessellations that cram way too many angles into one corner. The example of an “impossible” hyperbolic tessellation that I focused on in my implementation is the Order 5 square tiling, where 5 perfectly regular squares meet at each vertex. It may seem, under first viewing, that there is a total of 5*90= 450 degrees surrounding every vertex, but this is not true. At the small area around a point, hyperbolic space is essentially flat, and all angles around a vertex must add up to 360 degrees. Therefore each square must have 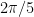

Quick tangent about ideal points: Ideal points (also called points at infinity), don’t exist on the hyperbolic plane, but instead exist as well defined points outside of it- on the poincare disc, they exist right at the circumference. Two ideal points exist at the “end” of any hyperbolic straight line. For any straight line A and point B, there is a set of lines through the point that don’t intersect with the line A, called parallel lines. There are two lines, called the left and right limiting parallels, that just barely don’t intersect with line A- and they are defined as sharing Ideal endpoints. If all endpoints of a polygon are Ideal points, the shape is called an Ideal polygon. All Ideal polygons with the same number of sides have 0 internal angle, and have the same finite area! Ideal polygons are clearly unique to hyperbolic geometry, and have unintuitive properties. For example, all ideal triangles are congruent, but this is not generally true ideal polygons with more than 3 sides. Take ideal quadrilaterals for example- if you were to join 2 congruent ideal triangles by on an edge, there is an infinite number of ways to do this, yielding non-congruent shapes, only because the infinitely long edge allowing for a range of different relative translations. Another way of thinking about this (courtesy of Marek Čtrnáct) is considering the angle between the diagonals of an ideal quadrilateral, which can differ between different instances.

Nearly every conceivable uniform tessellation (except for euclidean or spherical ones) can be constructed in hyperbolic space- here are a couple uniform tessellations and their Schläfli symbols {a,b}, which tells you there are a edges per face, and b faces around each vertex. For example, a cube would have the Schläfli symbol {4,3}, the dodecagon {5,3}, and a square 4 regular tessellation of the flat plane {4,4}.

You can also tesselate ideal polygons. For example, here is the tessellation of an ideal triangle, with the Schläfli symbol {3,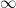

Other non uniform tessellations of hyperbolic space exist, with a variety of complexity.
All the geometric constructions we’ve mentioned so far are made entirely from straight lines, but curved lines in hyperbolic space also has its fair share of novel properties. By curved lines, I mean lines of constant curvature (in 2d), where every point on the curve is congruent to every other. In euclidean space, curvature is defined as 1/r, where r is the radius of a circle tangent to the curve, but for several reasons, this definition will not apply to curves in hyperbolic space. In euclidean space, there are 2 distinct curves- the straight line, and the circle. In hyperbolic space, there are 4 distinct curves of constant curvature- the straight line, hypercycle (also known as equidistants), horocycle, and hyperbolic circle. The two curves that have no analog in euclidean space are the hypercycle and horocycle- they have nonzero curvature but have no center on the hyperbolic plane. On the Poincare disc, all cycles of constant curvature appear as circles (or chords)- but only the hyperbolic straight line is meets the boundary at right angles. Below shows the main types of curves in blue.

In this visualisation, hyper-curves are approximated by linear segments with a constant angle between them- their implementation is described in the programming section of this blog post. But this approximation is sufficient to get a good understanding. The first thing worth breaking down is the reason are hypercycles are also known as equidistants. Equidistants in geometry describe the locus, or set of equidistant points at a certain distance from an object- for example a circle is an equidistant of a point. But the equidistant curve in hyperbolic geometry doesn’t refer to a circle, it refers to the one side of an equidistant set of a hyperbolic line. A points distance from a line is defined as the minimum distance between the point and any point on the line, or also the perpendicular distance. In euclidean space, an equidistant set of a line is just two parallel lines, but in non euclidean spaces, equidistant curves behave differently. In spherical geometry, a straight line is a great circle, like the equator, and equidistant curves are small circles parallel to the great circle. Small circles do not represent straight lines- any ship travelling on a line of latitude will constantly have to turn away from the equator as a straight line would naturally bring the two curves closer together, and as a result travels a shorter distance.

In hyperbolic space, the relationship is inverted. To travel along an equidistant, you would constantly have to turn towards the line, as as straight lines naturally diverge in hyperbolic space, and as a result of this, hyperbolic equidistants are longer than the straight line it was generated from. If you were walking on an equidistant curve at the same speed as someone walking on the generated straight line, you would find yourself lagging behind. Remember to always stay in the tailwind if you find yourself in a bike race in hyperbolic space. But why are equidistants always a constant curvature curve? Every point on a straight line is translationally symmetric and congruent, so every point on an equidistant is also congruent, so every point curves the same amount. In the rendering below, each curve is approximated by a series of segments, each with a transformation noting it’s position. For the straight line, these points can be generated by repeatedly applying a translation transform, but any repeated application of a hyperbolic affine transformation will result in a curve with constant curvature. The interesting/convenient thing I found in implementation, was you could easily find the affine transform defining each equidistant with simple code. Let’s say the affine translation defining the straight line is 


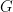



The Horocycle is a special limiting case of a hypercycle, where both ends of the cycle converge at the same ideal point. A specific curvature is needed for the horocycle to do this, too low- the hypercycle will have 2 distinct endpoints, too high- the curve will close into a bounded hyper circle. This exact curvature means all horocycles are congruent, and the equidistant sets of a horocycle are just more, congruent horocycles, making horocycles almost have a sense of parallelism, even though they aren’t straight lines. Horocycles can be interpreted as two things, a hypercycle with its generating line infinitely far away, or a circle with its center infinitely far away. Either way, the all perpendiculars of a horocycle converge to the point where the horocycle closes.

More information about hyperbolic space can be found across the internet, including the HypeRogue website, and CodeParade recently published a video about hyperbolic properties in his devlog series, which is definitely worth watching.
Implementation Iteration 1- Matrices
In the following sections of the blog post, I will be talking about my process of implementing the engine I used to produce much of the graphics in this post, and documenting the biggest challenges and insights. After each iteration, we will have a functioning implementation of the space, with navigation, but each iteration will add more efficiency, reduce numerical error and result in a more robust model with more features. It’s clear that hyperbolic space is riddled with exponentials, numbers can grow quite large and lose granularity, so each implementation will try to reduce the reliance on cold hard computation, and replace it with discrete systems to keep the numbers low. But that’s for later- first we need to implement the basic transformations that underpin the Minkowski space.
I made my simple framework in Java using the Processing library and IDE, not that it is the best for this purpose, but it is very easy to work with, and I recommend using it if you are just sketching things out and want an ultra-simple graphics library that supports 2d and 3d that won’t yell at you every five seconds. The first thing to do is draw a circle with a radius to the canvas- this circle represents the unit poincare disc projection. I defined the variable Scale to be half of the size of the canvas, and the radius of the circle.

To represent points in Minkowski space, I will be using the 3D PVector class, and to represent transformations, I will be using the 3D PMatrix class. Points on the hyperboloid are 3d vectors <x,y,z> such that

In order to render points to the poincare disc, we need to project the Minkowski hyperboloid down. Considering two similar triangles formed by the point before and after projection, a formula for the point after projection is not too hard to derive. The projectOntoPoincareDisc function returns a 2d vector on the poincare disc, with magnitude less than 1. A separate function called projectOntoScreen just scales up the projected vector by the radius of the circle.

With this, we can now render lines that pass through the origin, by drawing lines between points with varying radii in polar coordinates. Here, I’m drawing a line of length 1 consisting of 10 segments. Clearly this isn’t very interesting on its own, because lines from the origin of disc just appear as regular euclidean straight lines.

In order to get lines that don’t start at the origin, we need to make use of transformation matrixes to move the starting origin (By transformation, I mean a hyperbolic affine transformation holds the location and rotation information of a view on the Minkowski hyperboloid). To do this, we can make use of the PMatrix3D class, which stores 3D transformations, which are represented as 3×3 transformation matrix and a translation vector, which is part of a 4×4 transformation matrix- the 3d analog of 2d euclidean transformation matrix. But we won’t be using the translation component, because we are only using the PMatrix3D to represent transformations in 2d hyperbolic space. Ideally, I would write my own matrix class, but this is just a bodge.

By applying a transformation to the vector, we can effectively move it to any position/orientation in hyperbolic space. By multiplying several translation matrices, we can get a simple interactive view of how the points get transformed. In this sketch, I first translate in the Y direction by an amount proportional to the mouseY value offset form the center, and then translate in the X direction, to get a matrix defining where the line is being drawn.

//Iteration #1- Matrices
float Scale=400;//Radius of poincare disc in pixels
public void setup(){
size(800,800,P3D);
}
public void draw(){
background(0);
stroke(255,0,0);
strokeWeight(4);
float scaledMouseY=mouseY/Scale-1;
float scaledMouseX=mouseX/Scale-1;
//Draw poincare disc background.
circle(Scale,Scale,Scale*2);
//Draw a line
PMatrix transform=TranslationMatrixY(scaledMouseY*2f);
transform.apply(TranslationMatrixZ(scaledMouseX*2f));
drawLine(transform,0f,5f);
//circle at mouse
circle(mouseX,mouseY,3);
}
public void drawLine(PMatrix currentTransform,float angle,float lineLength){
PVector prevPoint= new PVector();
float inc=0.1f;
for(float i=0;i<lineLength;i+=inc){
PVector nextPoint= polarVector(i,angle);
//Apply currentTransform on nextPoint and save the result in nextPoint
currentTransform.mult(nextPoint,nextPoint);
nextPoint=projectOntoScreen(nextPoint);
if(i>=inc){
line(prevPoint.x,prevPoint.y,nextPoint.x,nextPoint.y);
}
prevPoint=nextPoint;
}
}
At this point, we have most of the tools we need to render stuff, so the task I gave myself now was to render an “infinitely” large order 5 square tessellation, with a player camera that can navigate across it. In order to render the lines and points that make up the order 5 square tessellation, I can begin by recursively drawing a tree that passes through every vertex once, starting at the of the tessellation. I adapted this infinite spanning tree idea from the tree-path address system used in HyperRogue (Which is something that I will implement in the Tree Traversal iteration).

But the tessellation used in HyperRogue is a regular heptagonal tessellation, but a tree for the 5 regular square tessellation can be generated in a similar manner. Consider 1 vertex in the tessellation as the origin and root of the tree, and construct edges radiating out in all 5 directions. These branches must be extended to cover every vertex in the tessellation. All vertices that aren’t the origin can be grouped into 5 sectors, the root of each sector being the 5 edges around the origin. I call the 5 red sectors in the 2nd figure 3 branched sectors, and they are always counterclockwise biased i.e contain the 3 counterclockwise most branches.

At this point we need to break down each sector- by constructing the 3 branches contained nearest to the origin in each 3 branched sector, all other points in the sector can be grouped into two 3 branched sectors on the clockwise side, and one 2 branched sector (green) on the counterclockwise side. A 2 branched sector contains the two edges opposite to the root edge. Lastly, the 2 branched sector can be broken down into another 2 branched sector and a 3 branched sector. Recursively breaking down each sector until an infinite tree is generated makes it clear that every vertex will be reached by said tree. Quite a longwinded way of saying we can generate a tree that renders the order 5 square tessellation with just two recursive functions: one that draws a 3 branched sector by drawing one 2 branched sector and two 3 branched sectors, and one that draws a 2 branched sector by drawing another 2 branched sector and 1 3 branched sectors, all in very specific locations- but the important part is that the relative locations of each sector is easy to calculate, just a combination of translation by the branch length, and rotations of multiples of

There is a lot of complexity here, which is worth going into more detail. By sector, I mean the infinite set of points and edges contained in a shape, originating from one point (sector origin vertex), and containing a large section of the plane. The two boundaries of the sector aren’t straight lines, but are approximate hypercycles. I note 2 distinct types of sectors, the 2 branched and 3 branched sectors, named because they contain 2 and 3 branches, and can be subdivided into 2 and 3 other sectors respectively. Each sector also is said to have a root edge, the edge in the tree that connects to the sector origin vertex, but isn’t a branch. All 3 branched sectors are geometrically congruent (and yes, the 3 branched sector can be subdivided into other exactly congruent sectors, because of the exponential nature of space), and all 2 branched sectors are congruent. For formality, I name each branch radiating from the sector origin (excluding the root), naming the counterclockwise most branch 0, and numbering the other 2 or 3 branches going clockwise. I also also assign a direction to every edge with a direction number, starting at the root with direction number 0, and counting up clockwise to 4. The 2 branched sector has branches in the 2 and 3 direction, ignoring directions 1 and 4. The 3 branched sector has branch 0 starting at direction 1 and ignoring direction 4.
By expanding each sector infinitely, we have every vertex being a sector origin, and every edge around it having an associated direction number relative to it.

The length of the branch can be determined by hyperbolic trigonometry to be around 1.255 units long. By implementing the functions draw2BranchSector, draw3BranchSector, and drawOrder5Tiling, we can draw an order 5 tiling of a given radius. The following graphic renders the tree at the same transformation used previously, with a radius of 3 branches.
public void draw(){
background(0);
stroke(255,0,0);
strokeWeight(4);
float scaledMouseY=mouseY/Scale-1;
float scaledMouseX=mouseX/Scale-1;
//Draw poincare disc background.
circle(Scale,Scale,Scale*2);
//Draw a order5SquareTessilation
PMatrix3D transform=TranslationMatrixY(scaledMouseY*2f);
transform.apply(TranslationMatrixZ(scaledMouseX*2f));
drawOrder5Tiling(transform);
//circle at mouse
circle(mouseX,mouseY,3);
}

The following are the functions that get called recurrently. Each function takes as input the transformation where it should start rendering and depth, and draws a single edge with the branch length at this location. But first it makes a copy of the given matrix, as not to corrupt the transform which may be used later. Then it translates the copied transformation by the branch length in the forward (z) direction, before choosing the correct rotation before passing the resulting matrix to the appropriate sector function (with incremented depth), only if the current depth is less than the maximum allowed depth. The correct rotation is achieved by first rotating by 180 degrees (PI), as a default angle pointing back into the edge previously drawn so that all further rotation refers to the angle between the segments to be generated and the root of the segment, e.g. the angles between the branches in a 3branchedSector and the sectors root are 

It’s interesting to reflect on how exactly this is working. We never explicitly wrote in the code that the vectors resulting from the polar coordinate function, or multiplication with hyperbolic affine transformation matrices, had to lie on the
float branchLength=1.255;
int Depth=3;
void drawOrder5Tiling(PMatrix3D currentTransform){
PMatrix3D transformCopy= new PMatrix3D();
transformCopy.set(currentTransform);
for(int i=0;i<5;i++){
transformCopy.apply(RotationMatrix(TWO_PI/5));
draw3BranchSector(transformCopy,0);
}
}
void draw3BranchSector(PMatrix3D currentTransform,int depth){
drawLine(currentTransform,0,branchLength);
PMatrix3D transformCopy= new PMatrix3D();
transformCopy.set(currentTransform);
transformCopy.apply(TranslationMatrixZ(branchLength));
transformCopy.apply(RotationMatrix(PI));
if(depth<Depth){
transformCopy.apply(RotationMatrix(TWO_PI/5));
draw2BranchSector(transformCopy,depth+1);
transformCopy.apply(RotationMatrix(TWO_PI/5));
draw3BranchSector(transformCopy,depth+1);
transformCopy.apply(RotationMatrix(TWO_PI/5));
draw3BranchSector(transformCopy,depth+1);
}
}
void draw2BranchSector(PMatrix3D currentTransform,int depth){
drawLine(currentTransform,0,branchLength);
PMatrix3D transformCopy= new PMatrix3D();
transformCopy.set(currentTransform);
transformCopy.apply(TranslationMatrixZ(branchLength));
transformCopy.apply(RotationMatrix(PI));
if(depth<Depth){
transformCopy.apply(RotationMatrix(TWO_PI/5));
//Line to complete the tiling
//drawLine(transformCopy,0,branchLength);
transformCopy.apply(RotationMatrix(TWO_PI/5));
draw2BranchSector(transformCopy,depth+1);
transformCopy.apply(RotationMatrix(TWO_PI/5));
draw3BranchSector(transformCopy,depth+1);
}
}
If you are wondering how to draw every edge in the tiling, not just the ones in the tree, the answer is in the commented out line of code. Surprisingly, we only need to draw one more line in the 2 branched sector function, that draws a single line at direction 1. This works because every edge that wasn’t drawn by the tree connects 2 sector origin vertices that ignored both respective directions. The left of an undrawn edge always connects to a vertex in direction 4, while on the right the edge connects to a vertex in direction 1- but only the 2 branched sector ignores direction 1, so drawing an edge there will effectively fill everything in.

void draw2BranchSector(PMatrix3D currentTransform,int depth){
drawLine(currentTransform,0,branchLength);
PMatrix3D transformCopy= new PMatrix3D();
transformCopy.set(currentTransform);
transformCopy.apply(TranslationMatrixZ(branchLength));
transformCopy.apply(RotationMatrix(PI));
if(depth<Depth){
transformCopy.apply(RotationMatrix(TWO_PI/5));
drawLine(transformCopy,0,branchLength);
transformCopy.apply(RotationMatrix(TWO_PI/5));
draw2BranchSector(transformCopy,depth+1);
transformCopy.apply(RotationMatrix(TWO_PI/5));
draw3BranchSector(transformCopy,depth+1);
}
}
Now the only thing left to do is to add a WASD navigation system, where the arrow keys will move the “camera” relative to an underlying 5 regular square tessellated floor. This isn’t too difficult: replace the mouse position dependent initial transformation with a stored variable, and have the arrow keys apply a small transformation to this variable. The up and down arrow keys will apply a small upward and downward transition to this transform, and the left and right arrow keys will apply a small counterclockwise and clockwise rotation respectively.
//Iteration #1- Matrices
float Scale=400;//Radius of poincare disc in pixels
PMatrix3D camTransform= new PMatrix3D();
public void setup(){
size(800,800,P3D);
}
public void draw(){
background(0);
stroke(255,0,0);
strokeWeight(4);
float scaledMouseY=mouseY/Scale-1;
float scaledMouseX=mouseX/Scale-1;
//Draw poincare disc background.
circle(Scale,Scale,Scale*2);
//Draw a order5SquareTessilation
drawOrder5Tiling(camTransform);
//circle at mouse
circle(mouseX,mouseY,3);
//check keypresses:
if(keyPressed){
if(keyCode==UP){
camTransform.apply(TranslationMatrixY(-0.04));// Translate Up
}else if(keyCode== DOWN){
camTransform.apply(TranslationMatrixY(0.04));//Translate down
}else if(keyCode== RIGHT){
camTransform.apply(RotationMatrix(-0.04));//Rotate clockwise
}else if(keyCode== LEFT){
camTransform.apply(RotationMatrix(0.04));// Rotate counterclockwise
}
}
}
But the moment you run this code, you’ll realise that It looks nothing like a camera moving through a space: instead things are still transforming (rotating and translating) relative to the origin of the tessellation, not the center of the camera. The root of this problem is something we will run into time and time again- covariant vs contravariant transformation rules. At this point, all the transformations we have worked with represent positions of objects relative to the space- but what we are trying to control with the the navigation is the transformation of the underlying coordinate itself. In this case, we want the underlying space to be the order 5 tessellation itself. In multivariable algebra/linear algebra, a tensor/vector is covariant if it transforms along with the basis vectors, and contravariant if it transforms inversely. The origin of the tessellation acts like a basis, and therefore behaves inversely compared to transformations to points on the space. So in order to move the space around the camera and not the other way around, we need to apply the inverse of our camera transform. To do this, you could find the inverse transform, but processing’s inverse function is broken, but there is a simple workaround using understanding of inverse matrices.

Instead of storing the camTransform variable- the transform of the camera relative to the tessellation origin, lets call the matrix 




public void draw(){
background(0);
stroke(255,0,0);
strokeWeight(4);
float scaledMouseY=mouseY/Scale-1;
float scaledMouseX=mouseX/Scale-1;
//Draw poincare disc background.
circle(Scale,Scale,Scale*2);
//Draw a order5SquareTessilation
drawOrder5Tiling(camTransform);
//circle at mouse
circle(mouseX,mouseY,3);
//check keypresses:
if(keyPressed){
if(keyCode==UP){
camTransform.preApply(TranslationMatrixY(0.04));
// Translate Up (down because inverse A)
}else if(keyCode== DOWN){
camTransform.preApply(TranslationMatrixY(-0.04));
//Translate down
}else if(keyCode== RIGHT){
camTransform.preApply(RotationMatrix(-0.04));
//Rotate clockwise
}else if(keyCode== LEFT){
camTransform.preApply(RotationMatrix(0.04));
// Rotate counterclockwise
}
}
}
Thats much better. It actually looks like we are walking around hyperbolic space now. Time to move on and implement infinite generation, geometry, and etc, right? Wrong. If you far away from the origin and attempt to come back, or just move around a bunch you will find that everything breaks down and goes to high hell. This is an issue with using a matrix to represent the camera transformation- the only reason the matrix continues to represent an affine hyperbolic transformation after repeated multiplication of small translations/rotations is mathematical coincidence, and it can quickly break down- especially if you move a large distance from the origin. In order to fix this issue, we have to build a more robust way of representing transformations.

Implementation iteration 2- Polar Transform
There are several ways I could’ve solved the matrix error issue. The first idea I had was a way of normalising the matrix- to turn a broken transformation into one that represents a true affine transform. This solution has its benefits, and is what is used in Hyperrogue (using Gram-Schmidt ortogonalization, essentially projection). For one, we can continue using the PMatrix3d class to represent transformations, which is computationally efficient because it uses matrix multiplication to apply transforms, which calls no complex functions and can be parallelised. Also with this solution, we only need to call the normalising function once in a while when things deviate too far. I chose not to use this solution for a couple of reasons. Matrices are hard to work with- as we saw before inverses are expensive and bug prone, and matrices don’t give you very much useful information- e.g. the magnitude of the translation in the transform.
The better solution is one that better represents the nature of affine transformations. I said earlier in this post that transforms are best represented by something I call the polar transform: a combination of rotations and translations that parametrises any affine transform.
Every affine transform results in the origin being translated to a new point in the space, and this new point is best represented by a polar vector. Note that the first two transformations that make up the polar transform, which we will call N and R effectively moves the origin to the point with polar coordinates (r,n), as can be seen with the following matrix multiplication. The final rotation by m radians does not effect the origin’s transformation.

Every affine transformation can be represented by a polar transformation because every transform is essentially a translation of the origin (NR) and a rotation relative to that point (M). For example, a translation of a distance r in the z direction can be represented by 

public class PolarTransform{
//A parametrisation SU2 that preserves hyperbolic space.
//Starts with rotation of n rad,
//translation in y of s, and a rotation of m
float n;
float s;
float m;
PolarTransform(){
}
PolarTransform(float dN,float dS, float dM){
n=dN; s=dS; m=dM;
}
PMatrix3D getMatrix(){
PMatrix3D startTransform=RotationMatrix(n);
startTransform.apply(TranslationMatrixZ(s));
startTransform.apply(RotationMatrix(m));
return startTransform;
}
}
So what would a multiplication function look like? Essentially we are trying to solve this math problem- given 2 polar transforms 


Not an easy problem by any measure. The function applyPolarTransform takes as input the polar transform (
void applyPolarTransform(PolarTransform pt){
applyRotation(pt.n);
applyTranslationZ(pt.s);
applyRotation(pt.m);
}
The first function, applyRotation( float a) is quite simple, luckily- because the polar transform ends with a rotation matrix, and applying a rotation matrix to another rotation matrix simply adds the angles together (something out of plain old linear algebra).

void applyRotation(float a){
m= m+a;
}
The second function applyTranslationZ(float l) isn’t as trivial though, we essentially have to fully expand the matrices before we can start comparing values. Starting with the resulting polar transform (

This matrix has to exactly equal the matrix resulting from the application of a translation in the z direction a distance of l :

Given that these two matrices are equal, how do we solve for the 











Solving for the angles 




By taking a ratio:
But we can’t necessarily say that 

We can find the value of
Therefore,
Implementing all of these expressions in a transformation function yields:







void applyTranslationZ(float l){
float N= atan2((cos(n)*sin(m)+cos(m)*sin(n)*cosh(s))*sinh(l)+sin(n)*sinh(s)*cosh(l),((cos(m)*cos(n)*cosh(s)-sin(m)*sin(n))*sinh(l)+cos(n)*cosh(l)*sinh(s)));
float S= arcosh(cosh(l)*cosh(s)+cos(m)*sinh(l)*sinh(s));
float M= atan2((sin(m)*sinh(s)),(cosh(s)*sinh(l)+cosh(l)*sinh(s)*cos(m)));
n=N;
s=S;
m=M;
}
A similar and very symmetric process can be done for a transformation in the Y direction yielding the following function:
void applyTranslationY(float l){
float N= atan2((cos(m)*cos(n)-cosh(s)*sin(m)*sin(n))*sinh(l)+cosh(l)*sinh(s)*sin(n),(-cos(n)*cosh(s)*sin(m)-cos(m)*sin(n))*sinh(l)+cosh(l)*sinh(s)*cos(n));
float S= arcosh(cosh(l)*cosh(s)+sin(m)*sinh(l)*sinh(s));
float M= atan2(-(cosh(s)*sinh(l)+cosh(l)*sinh(s)*sin(m)),(cos(m)*sinh(s)));
n=N;
s=S;
m=M;
}
Also, for the sake of completeness I wrote the functions for the pre-application of every transform also.
void preApplyTranslationY(float l){
float N= atan2(sin(n)*sinh(s),cosh(s)*sinh(l)+cos(n)*cosh(l)*sinh(s));
float S= arcosh(cosh(l)*cosh(s)+cos(n)*sinh(l)*sinh(s));
float M= atan2(cos(m)*sin(n)*sinh(l)+sin(m)*(cos(n)*sinh(l)*cosh(s)+cosh(l)*sinh(s)),cos(m)*(cos(n)*cosh(s)*sinh(l)+cosh(l)*sinh(s))-sin(m)*sin(n)*sinh(l));
n=N;
s=S;
m=M;
}
void preApplyTranslationZ(float l){
float N= atan2(cosh(s)*sinh(l)+cosh(l)*sinh(s)*sin(n),cos(n)*sinh(s));
float S= arcosh(cosh(l)*cosh(s)+sin(n)*sinh(l)*sinh(s));
float M= atan2(-cos(m)*cos(n)*sinh(l)+sin(m)*(cosh(s)*sinh(l)*sin(n)+cosh(l)*sinh(s)),cos(n)*sin(m)*sinh(l)+cos(m)*(cosh(s)*sinh(l)*sin(n)+cosh(l)*sinh(s)));
n=N;
s=S;
m=M;
}
void preApplyRotation(float a){
n+=a;
}
void preApplyPolarTransform(PolarTransform pt){
preApplyRotation(pt.m);
preApplyTranslationY(pt.s);
preApplyRotation(pt.n);
}
This is by far the most math heavy section of the implementation (its over!), now we can reap the conveniences this class grants us. For one, getting the inverse of a polar transformation is trivial. As I noted before, the inverse of a product of matrices both inverts each matrix individually and flips the order of multiplication, so the inverse of a polar transform negates each n,r,m value, and (due to the symmetry of the matrices) swaps the n and m value. In other words 
PolarTransform inverse(){
return new PolarTransform(-m,-s,-n);
}
How about finding the distance between two points given their polar transforms, also a piece of cake. Find the transform that gets one point to the other by multiplying one by the others inverse, and then return the r value (length) of this transform.
float distanceTo(PolarTransform p){
PolarTransform c= copy();
c.applyPolarTransform(p.inverse());
return c.s;
}
PolarTransform copy(){
return new PolarTransform(n,s,m);
}
At this point, we can finally put these classes and methods to use by replacing our camTransform matrix with a polar transform:
PolarTransform camTransform= new PolarTransform();
public void draw(){
background(0);
stroke(255,0,0);
strokeWeight(4);
float scaledMouseY=mouseY/Scale-1;
float scaledMouseX=mouseX/Scale-1;
//Draw poincare disc background.
circle(Scale,Scale,Scale*2);
//Draw a order5SquareTessilation
drawOrder5Tiling(camTransform.getMatrix());
//circle at mouse
circle(mouseX,mouseY,3);
//check keypresses:
if(keyPressed){
if(keyCode==UP){
camTransform.preApplyTranslationZ(0.04);// Translate Up (down because inverseA)
}else if(keyCode== DOWN){
camTransform.preApplyTranslationZ(-0.04);//Translate down
}else if(keyCode== RIGHT){
camTransform.preApplyRotation(-0.04);//Rotate clockwise
}else if(keyCode== LEFT){
camTransform.preApplyRotation(0.04);// Rotatate counterclockwise
}
}
}

What a ton of work to get no visual difference whatsoever! But that’s how we know things are working perfectly. You’ll be happy to know that you can go as far as you want from the origin and come back without any world destroying issues now.
At this point, we are only representing the camera transform with a polar transform object. Moving forward with the implementation, we need to create a class that stores the lattice points, and generates new points when we run into them.
Implementation iteration 3- Tree Traversal
In order to create a infinite hyperbolic world, instead of just a number of edges arranged in the right locations, I made use of 4 abstractions/classes. The first is the lattice coordinate, which gives a label/code to every vertex in the order 5 square tiling. The second is the lattice point, which represents a point on the tiling- it has a lattice coordinate and has attached objects. An arraylist of lattice points essentially represents the generated world. The third is the lattice walker, which is attached to and stores a lattice point and a direction relative, as well as a polar screen-view transform, and a camera relative lattice coordinate. Lattice walkers live on-top of the lattice point space, and can move freely. An array of lattice walkers centered around the camera are created and destroyed when navigating through the space and are used to render the visible lattice points. The final class is a Lattice system class that stores all the lattice points and lattice walkers.
A lattice coordinate gives a label/code to every vertex in the order 5 square tiling. The code for each vertex is an array of integers that (from left to right) tells you which branches to take in order to reach it. The length of the array can also gives you a measure of how far away a point is from the origin. For example, the origin has the lattice coordinate <> (empty), and has an array length of 0. The point at lattice coordinate <4,0,0> can be reached by taking the 4th branch, then the 0th branch, and the 0th branch again. The value at index 0 of the coordinate ranges from 0 to 5, and tells you which section the vertex is in. All subsequent values range from 0 to 2, and are subject to some rules. The value at index 1 range from 0 to 2 because these points are the start of a 3 branched sector and have 3 branches. The values at indexes greater than 1 (lets call the index i) follow the simple rule saying if value at index i-1 is 0, the value at index i must be 0 or 1.

To make sense of this, I like to think of the distinct types of vertices, and how we can traverse from them. The 3 types of vertices are the Origin, 2 Branched and 3 Branched. The coordinate for the Origin is always <>, and we define an arbitrary direction to be the 0 direction. Traversing from the origin in the direction r (
2 Branched vertices always have a coordinate array ending in 0, because branch 0 always represents the counterclockwise most branch, which always leads to a 2 branched vertex in our tree formulation. Let’s now consider the effect of traversing from a 2 branched point in various directions. Remember that direction 0 from a vertex points towards its root vertex, and all other direction numbers are defined clockwise from this. Traversing in the 0 direction essentially decreases the array length by 1 and removes the last entry in the array. eg. starting from point <4,0> traversing in the 0 direction will take you to point 4. For a 2 branched vertex, traversing in direction 2 is the same as taking branch 0, and traversing in direction 3 is the same as taking branch 1. Taking either of these directions appends the value 0 or 1 to the end of the coordinate array. e.g. Starting from point <3,0>, traversing in direction 2 yields <3,0,0> and traversing in direction 3 yields <3,0,1>. Traversing in directions 1 or 4 result in wholly different coordinate values, but we will be writing functions to deal with this.
3 branched vertices have coordinate arrays that end with a value that isn’t 0, the only exception being the point <0>. Traversing in direction 0 will also lead to the vertex’s root, and traversing in directions 1,2,3 will be equivalent to taking branched 0,1,2 respectively and will append the appropriate branch number to the end of the coordinate array. Only traversing in direction 4 leads to more complexity for 3 branched vertices.
Knowing this, a lattice coordinate of the form <….., 0,r> refers to a point that is one branch away from a 2 branched vertex, so it makes sense that r must be 0 or 1.

While implementing the LatticeCoord class which stores the path array and provides useful functions, I found it useful to store the vertex type as an LatticeType enum, with ORIGIN, BRANCH2, BRANCH3, INVALID as the possible values. INVALID is for an instance with a coordinate array that doesn’t represent a real point, which is useful for debugging when we write the traversal functions. The LatticeType of a given LatticeCoord can be easily be found- If the coord array length is 0, the LatticeType is ORIGIN. Next we have to check if the coord is invalid. If coord[0]>4, or if any other value is out of bounds, the coord is invalid. By looping through every index in the coord array, and keeping track of the previous value, we can check if any index value is out of bounds. Finally, if the coord array is valid, we can determine whether the point is a BRANCH2 or BRANCH3. If the array length is 1, the point is BRANCH3. Otherwise, we can check the last value. If it is 0, the point is BRANCH 2, otherwise BRANCH3.
enum LatticeType {ORIGIN,BRANCH2,BRANCH3,INVALID};
class LatticeCoord implements Comparable{
int[] coord; //Coordinate array
LatticeType type; //Type of point
LatticeCoord(int[] dCoord){
coord= dCoord;
type=findType();
}
int[] getCoord(){
return coord;
}
LatticeType findType(){
if(coord.length==0){ // If the array is empty, it is ORIGIN
return LatticeType.ORIGIN;
}
//Checking for validity
if(coord[0]>4){
return LatticeType.INVALID;
}
int prev=1;
for(int i=1;i<coord.length;i++){
if(prev==0&&coord[i]>1){
return LatticeType.INVALID;
}
if(prev>0&&coord[i]>2){
return LatticeType.INVALID;
}
prev=coord[i];
}
//Checking whether BRANCH2 or BRANCH3
if(coord.length==1){
return LatticeType.BRANCH3;
}
if(coord[coord.length-1]==0){
return LatticeType.BRANCH2;
}
return LatticeType.BRANCH3;
}
...
The most complex and useful function that we need to develop before we can create the illusion of infinite space is the traversal function, that tells you the new lattice coordinate you will reach after travelling in a direction. The aforementioned trivial cases can be implemented with a couple of array functions that remove the last element, or append a new value to an integer array.
static int[] copyArray(int[] a){
int[] b= new int[a.length];
for(int i=0;i<b.length;i++){
b[i]=a[i];
}
return b;
}
static int[] removeLastElement(int[] a){
if(a.length==0){ return new int[0];};
int[] b= new int[a.length-1];
for(int i=0;i<b.length;i++){
b[i]=a[i];
}
return b;
}
static int[] appendElement(int[] a, int e){
int[] b= new int[a.length+1];
for(int i=0;i<a.length;i++){
b[i]=a[i];
}
b[a.length]=e;
return b;
}
First we can implement the trivial cases in the coordInDirection function that returns a new LatticeCoord in the given direction. Firstly we take the direction mod5 to ensure that the direction is between 0 and 4 inclusive. If our lattice coord is invalid, we return null because we can make no statement. Next, we can deal with the exception if our lattice coord is the origin, which simply returns the latticeCoord with a coordinate array with 1 value, the given direction. Next, if the direction is 0, we return the latticeCoord before this one in the tree, by returning a new latticeCoord with the same coordinate array but with the last element removed. This will work for any latticeCoord, except the origin, which is why we do this after. We can deal with the lattice coords of type BRANCH2, with the simple cases in direction 2, and 3- and the type BRANCH3 in the directions 1,2 and 3, which involve appending the associated branch number for each one.
LatticeCoord coordInDirection(int direction){
direction = direction%5;
int[] coordT;
if(type==LatticeType.INVALID){
return null;
}
if(type==LatticeType.ORIGIN){
return new LatticeCoord(new int[]{direction});
}
if(direction==0){
return new LatticeCoord(removeLastElement(coord));
}
if(type== LatticeType.BRANCH2){
switch(direction){
case 1:
// Complexity
case 2:
return new LatticeCoord(appendElement(coord,0));
case 3:
return new LatticeCoord(appendElement(coord,1));
case 4:
// Complexity
}
}
if(type== LatticeType.BRANCH3){
switch(direction){
case 1:
return new LatticeCoord(appendElement(coord,0));
case 2:
return new LatticeCoord(appendElement(coord,1));
case 3:
return new LatticeCoord(appendElement(coord,2));
case 4:
// Complexity
}
}
return null;
}
To implement the nontrivial cases we need to observe how we can interpret these traversals as the result of traversals we already understand. The simplest case where we can see how to do this is the case of taking direction 4 on a BRANCH2 latticeCoord, because taking direction 4 can always be broken down into taking direction 0, branch 1 and branch 0, as this goes the other way around the square. For example, taking direction 4 from <4,0,0> – going direction 0 gives <4,0>- going branch 1 gives <4,0,1>- and going branch 0 gives <4,0,1,0>. Generally starting from <a,…,b,0> takes you to <a,…,b,1,0>. This can be implemented by setting the last element of a copy of the coords array to 1 and appending a 0.

if(type== LatticeType.BRANCH2){
switch(direction){
...
case 4:
coordT= appendElement(coord,0);
coordT[coordT.length-2]=1;
return new LatticeCoord(coordT);
}
}
This case is the simplest, because there is only one distinct way the branches can be arranged around it. Consider taking direction 1 from a BRANCH2 latticeCoord, there are many different arrangements. I found 6 distinct types of latticeCoords that have slightly different rules for traversing in the nontrivial directions, which I will color by type. For the BRANCH2 coords we can find the root BRANCH3 coord, by taking direction 0 until we find the 1st coord that isn’t BRANCH2. This is also the same as removing all the 0’s from the end of the coord, eg <4,0,0,0>’s root BRANCH3 coord is <4>. The green point’s root BRANCH3’s coords always ends in a BRANCH3 point connected to its parents branch 2, i.e. they will follow the form <…..,2,0…,0>, like <0,1,2,0,0,0,0,0>. A red point’s root BRANCH3’s coord always ends in a point connected to its parent’s branch 1 or to the origin, i.e. they will always follow the form <….,1,0….,0>, or <r,0…,0>, like <0,2,1,0,0,0> or <4,0,0,0>.

I call the green points 2ndBranchRooted, because it is rooted on the 2nd branch of a BRANCH3 point. We can find whether a BRANCH2 point is 2ndBranchRooted by finding the index in coord array where all elements after are 0. First we can safely remove the last element from the coord array and copy this into a temporary array coordT, because we know the last element of the coord array for a BRANCH2 point is always 0, by definition. By setting a variable ind equal to the last element’s index and decrement it down until coordT[ind] isn’t 0 or ind is 0, we have the index of the end of the BRANCH3 root. If coordT[ind]>1, we know it is connected at branch 2 is true. Also if ind==0, we are connecting at the origin so it should also be true.
switch(direction){
case 1:
coordT=removeLastElement(coord);
int index= coordT.length-1;
while(coordT[index]==0&&index>0){
index--;
}
boolean Branch2Rooted=false;
if(index>=1){
if(coordT[index]>1){
Branch2Rooted=true;
}
}
if(index==0){
Branch2Rooted=true;
}
...
The geometrical process for finding the coord after traversing in direction 1 is essentially the same for Branch2Rooted points and non Branch2 rooted points, but the exact algorithm for finding it is slightly different. The geometry of the tree cuts up the space into these infinite streets of squares, and crossing the street in order to take direction 1 involves going back along the street a number of steps, crossing it at the end of the street, and going up the same number of steps on the other side. In order to see the difference between in algorithm, let’s compare 2 seemingly congruent points. The point <4,0,1,2,0,0> is a Branch2Rooted point, while <4,0,1,2,1,0,0> isn’t. They both need to take the same number of steps (2) in order to reach their BRANCH3 root, and this process is the same for both, taking them to points <4,0,1,2> and <4,0,1,2,1> respectively. At this point, we need to cross the street, by taking direction 0 again, leading to the points <4,0,1> and <4,0,1,2,> respectively. The difference comes in when the points need to go back up the streets. The first step up is again the same for both cases- the rule being take the branch with number 1 less than the value at the index ind we previously calculated, this will result in the branch pointing 1 notch counterclockwise relative to the branch we just came from. For the Branch2Rooted point, ind is 3, with a value of 2, telling us to take branch 2-1 =1. For the non-Branch2Rooted point, ind is 4 with a value of 1, telling us to take branch 0. Taking one step back up the street takes us to the points <4,0,1,1> and <4,0,1,2,0> respectively. Implementing this, we decrement the value at coordT[ind] by 1, then take mod5 to deal with the case <0,0….>. The 2nd step up the street, on the other hand, is different across 2BranchRooted and non 2BranchRooted points, and it is the only difference between them! For 2BranchRooted points, going up the street just involves taking branch 2 repeatedly, but for non 2BranchRooted points, we must take branch 1 first since we reach a BRANCH2 point, but after that we continue taking branch 2. So after the 2nd step up, we reach points <4,0,1,1,2> and <4,0,1,2,0,1>. To implement the coordT after stepping back up, we increment ind and fill in the appropriate values, until the entire array is overwritten with 1’s or 2’s. The fact that we removed the last element from coordT is also important, because it makes sure the array is of correct length.

switch(direction){
case 1:
coordT=removeLastElement(coord);
int index= coordT.length-1;
while(coordT[index]==0&&index>0){
index--;
}
boolean Branch2Rooted=false;
if(index>=1){
if(coordT[index]>1){
Branch2Rooted=true;
}
}
if(index==0){
Branch2Rooted=true;
}
coordT[index]=(coordT[index]-1+5)%5;
index+=1;
if(index<coordT.length){
if(Branch2Rooted){
coordT[index]=2;
}else{
coordT[index]=1;
}
index++;
while(index<coordT.length){
coordT[index]=2;
index++;
}
}
return new LatticeCoord(coordT);
...
The last complex case (taking direction 4 on a BRANCH3 point), is functionally the inverse of the case we just dealt with, and it’s easier because the sub-cases are easier to identify. Note that the coord array after traversing in direction 4 is always one longer by one.

Also note that going back up the street involves only taking branch 0, and effectively the last part of the coord array is replaced by 2’s. In order to go down the street, we decrement and ind variable until we reach an element that doesn’t have a value of 2, meanwhile replacing all 2’s with 0’s. Once we reached an element with a value that isn’t 2 or ind ==0, there are 2 cases we have to deal with. If coordT[ind-1] ==0, it means ind refers to a BRANCH2, and we need to go down one more by setting coordT[ind-1] =1 and coordT[ind] =0. If coordT[ind-1]>0 or ind == 0, the case is analogous to the 2BranchRooted situation, and we can just increment coordT[index] by 1.
if(type== LatticeType.BRANCH3){
switch(direction){
...
case 4:
if(coord.length==1){
return new LatticeCoord(new int[]{(coord[0]+1)%5,0});
}
coordT= appendElement(coord,2);
int index=coordT.length-1;
while(coordT[index]==2&&index>0){
coordT[index]=0;
index--;
}
if(index==0||coordT[index-1]!=0){
coordT[index]= (coordT[index]+1)%5;
return new LatticeCoord(coordT);
}
coordT[index-1]=1;
coordT[index]=0;
return new LatticeCoord(coordT);
}
}
One last thing we need to keep track of before we can implement latticeWalkers that can traverse independently is the direction you end up after traversing in a direction i.e. if you traverse in a direction from the point A to point B, what direction from B would you have to go to get back to A? If we go in a direction that has an associated branch, the back direction is 0, because that returns a point to its root. If you go in direction 0, the direction you have to go to get back is the direction that refers to the branch point A is rooted to. I call this direction the leaf direction of a latticeCoord, because it is the direction of the last edge , the “leaf” relative to its root’s coordinate. The directionOfLeaf function implements this by first figuring out the coordType of the root coordinate, and using that to specify which branch numbers refer to which directions, also dealing with the special case of the points around the origin.
int directionOfLeaf(){
if(coord.length==0){
return 0;
}
if(coord.length==1){
return coord[0];
}
boolean branch3=false;
if(coord.length==2){
branch3=true;
}else{
if(coord[coord.length-2]!=0){
branch3=true;
}
}
if(branch3){
return (coord[coord.length-1]+1);
}else{
return (coord[coord.length-1]+2);
}
}
The last thing to note, taking direction 4 can always be undone by traversing back in direction 1, and vice versa, which is quite convenient.
int directionAfterTravel(int direction){
direction = direction%5;
if(type==LatticeType.INVALID){
return -1;
}
if(type==LatticeType.ORIGIN){
return 0;
}
if(direction==0){
return directionOfLeaf();
}
if(type== LatticeType.BRANCH2){
switch(direction){
case 1:
return 4;
case 2:
return 0;
case 3:
return 0;
case 4:
return 1;
}
}
if(type== LatticeType.BRANCH3){
switch(direction){
case 1:
return 0;
case 2:
return 0;
case 3:
return 0;
case 4:
return 1;
}
}
return -1;
}
Implementation iteration 4- Infinite generation,
Implementation iteration 5- Structure generation
Both infinite generation and structure generation (which are arguably the same thing), can be created with one generalization: the tile system. Every tile has a coordinate in global space, but the actual path used to find the exact transform used to render said tile, is calculated relative to the camera origin. As the camera origin changes, so does the relative path, but not the global path. The position of the camera, of course, is a one of these tiles also, with an added polar transform, with the restriction that the tile it is rooted to is the closest to the camera position, this can be insured by checking the magnitude of the polar transform associated with the camera. If after adding translations by 1 unit in each of the 5 direction yields the original magnitude as the least, the tile is not changed, otherwise, the new least magnitude sets the camera origin tile to that least direction, updating the relative path of all objects rendered- also only rendering the tiles a certain number of steps away from the camera. Structures- objects with a certain position- function similarly to the camera, and are fixed on top of a certain tile. Structures can be procedurally loaded in and out with the tiles, with a certain check for if a newly generated tile hosts a structure.
Since a lot of this is business logic built on top of the systems described earlier, I will not be going into all the technical details. If you are implementing this, consider viewing my source code. Also, make sure to keep track of forward and backward transformations.
Extras- Generating 3d models
Inspired by Henry Segerman’s work in Visualizing Mathematics with 3D printing, and his video on Illuminating Hyperbolic space, I decided to create my own version of the Hyperbolic Half Sphere projection model, which I created using the Processing plugin HEMesh by wblut.
I proceeded to print it out myself, which was much more difficult than I expected, with the huge overhangs, on a standard filament deposition 3d printer. Do not even bother to attempt if you don’t have fancy powder printing systems, or a printer with 2 extruders and soluble support filament. If that doesn’t scare you, the file is available on Thingiverse for free.

I do concede that the model has all kinds of strange artifacts, but I think it just adds to the hacker charm.
Maybe that was enough talking about hyperbolic space, huh.
If you reached here, you are probably one of a kind. Hope you learned a bit about something, and I really do recommend trying to implement this- it is quite fulfilling. Thank you for hearing what I have to say about a strange, unnatural geometrical space that has no place in physical reality, other than strange crochets and spacetime representations. I guess you could say it is all just some pointless conjecture (yes I always have to make a call back). Thanks for reading!

The Poincaré projection is not the only conformal projection of hyperbolic space (in 2D). It _is_ the only one with circle boundary, though. (There’s a variety of conformal projections in 2D, each corresponding to an analytic function from complex analysis. You can compose the Poincaré projection with any of those.)
In 3D and up, though, the Poincaré projection _is_ the only conformal projection. This is because, in more than two dimensions, the only conformal projections – besides dilations and rigid motions – are so-called Möbius transformations, which, when composed with the Poincaré projection, are the same as precomposing a hyperbolic translation.
LikeLike
Absolutely amazing introduction. I’ve been curious about how to work with and project hyperbolic tessellations into euclidean space for creative visualization. Thank you so much for the processing starter code and all the different ways of processing and mapping the information; lots to digest!
LikeLike
You’re welcome!
LikeLike